The Data Standardlizing and Preprocessing process focuses on unifying the columns’ name, labelling those parcels without address, removing duplicate geometries and ensuring the integrity of the Tarrant Parcels and Road datasets. Due to data quality issues, some geometries in both datasets have identical attributes but are repeated. This process involves identifying and eliminating these redundant geometries while ensuring that key information, such as address names, is retained. After this process, the datasets are transformed into a consistent format and prepared for further spatial analysis.
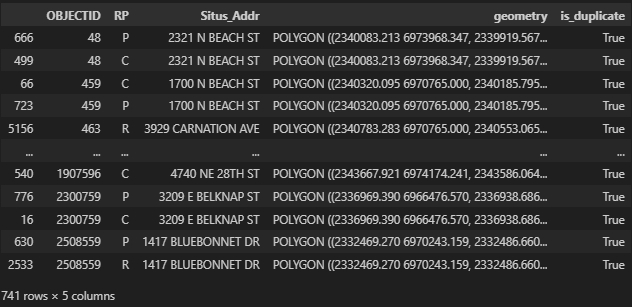
In the selected parcels of Tarrant County, there are some duplicated geometries(741/5311), which usually share the same address attributes. Figure 1: An example of duplicated parcels, created by Houpu Li
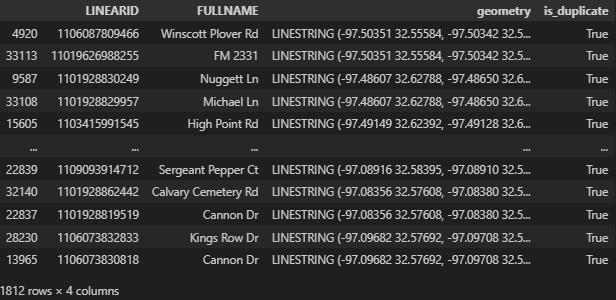
In the road centerline dataset of Tarrant County, there are some duplicated geometries(1812/41202), which usually share the different address attributes. Figure 2: An example of duplicated roads, created by Houpu Li
01.Preprocessing for Parcels
This section details the data cleaning process for the tarrant_parcel dataset, including CRS transformation, removal of duplicate geometries, standardization of column names (handling cases where OBJECTID and OBJECTID_1 refer to the same attribute), labeling parcels with missing address information, and resetting the index.
Note:
In the original dataset, both Prop_ID and OBJECTID columns are present and serve as parcel identifiers. However, after inspection, Prop_ID is found to be truly unique, while OBJECTID contains about 10% duplicate values. And the official documentation from TxGIO, there is no explanation for OBJECTID. For more details, see here. From this section through step 6: Label Parcel Edges, we rename OBJECTID (or OBJECTID_1) to parcel_id for data analysis and processing. In step 7: Generate Results, we reconstruct the parcel_id by assigning new sequential values starting from 1, since OBJECTID is inaccurate and redundant compared to the unique Prop_ID.
Code
# Tarrant Parcel:'''read the parcel and standardlizing the column name'''# define file pathparcel_path =r'Tarrant_County/ParcelView_Tarrant.zip'# standlize the column namesparcel_cols = {'OBJECTID': 'parcel_id', 'OBJECTID_1': 'parcel_id', 'SITUS_ADDR': 'parcel_addr', 'STAT_LAND_': 'landuse_spec'}# read the dataparcel = gpd.read_file(parcel_path)# rename the columnsparcel.rename(columns=lambda x: parcel_cols.get(x, x), inplace=True)'''parcel preprocessing'''# Define a function to extract only the road name part (before the first comma)def optimize_road_name(situs_addr):if pd.isna(situs_addr) or situs_addr.strip() ==', ,':returnNoneelse:return situs_addr.split(',')[0].strip()# Apply the function to the 'SITUS_ADDR' columnparcel['parcel_addr'] = parcel['parcel_addr'].apply(optimize_road_name)parcel['parcel_addr'] = parcel['parcel_addr'].replace(r'^\s*$', None, regex=True)'''extract residential area based on specifical landuse'''parcel['landuse'] = parcel['landuse_spec'].apply(lambda x: 'R'ifisinstance(x, str) and x[0] in ['A', 'B'] elseNone)'''read the parcel data and data cleanning, tips: steps 3 and 4 are necessary to remove duplicate geometries and ensure that the remaining rows contain the required address information.'''# Step 1: Transfer the CRS to 4326parcel = parcel.to_crs(4326)# Step 2: Create a column to indicate whether 'parcel_addr' or 'landuse' has a value (True/False)parcel['has_info'] = (~parcel['parcel_addr'].isna()) | (~parcel['landuse'].isna())# Step 3: Sort the rows by 'has_info' in descending order to prioritize rows with parcel_addr or landuse valuesparcel = parcel.sort_values(by='has_info', ascending=False)# Step 4: Drop duplicates based on geometry, keeping the first occurrence (which now has priority rows at the top)parcel = parcel.drop_duplicates(subset='geometry')# Step 5: Drop the 'has_info' column as it's no longer neededparcel = parcel.drop(columns=['has_info'])# Step 6: Initialize 'parcel_labeled' column with None valuesparcel['parcel_label'] =Noneparcel.loc[parcel['parcel_addr'].isna(), 'parcel_label'] ='parcel without address'parcel = parcel.reset_index(drop=True)# Step 7: Extracted the useful columnsparcel = parcel[['Prop_ID','GEO_ID','parcel_id','parcel_addr','landuse','landuse_spec','parcel_label','geometry']]# Step 8: Group the duplicate parcel_id values and add a suffix.parcel.loc[parcel['parcel_id'].duplicated(keep=False), 'parcel_id'] = ( parcel.loc[parcel['parcel_id'].duplicated(keep=False), 'parcel_id'].astype(str) +'_'+ parcel.loc[parcel['parcel_id'].duplicated(keep=False)].groupby('parcel_id').cumcount().add(1).astype(str))
The code performs data cleaning on the tarrant_road dataset by transforming the CRS, removing duplicate geometries, and resetting the index.
Code
# Tarrant Roads:# define file pathroad_path =r'Tarrant_County/tl_2023_48439_roads_Tarrant.zip'# standlize the column namesroad_cols = {'LINEARID': 'road_id', 'FULLNAME': 'road_addr'}# read the dataroad = gpd.read_file(road_path)# rename the columnsroad.rename(columns=lambda x: road_cols.get(x, x), inplace=True)'''read the road data and data cleanning'''# Step 1: Transfer the CRS to 4326road = road.to_crs(4326)# Step 2: Create a column to indicate whether 'road_addr' has a value (True/False)road['has_info'] =~road['road_addr'].isna()# Step 3: Sort the rows by 'has_info' in descending order to prioritize rows with Situs_Addr or RP valuesroad = road.sort_values(by='has_info', ascending=False)# Step 4: Drop duplicates based on geometry, keeping the first occurrence (which now has priority rows at the top)road = road.drop_duplicates(subset='geometry')# Step 5: Drop the 'has_info' column as it's no longer neededroad = road.drop(columns=['has_info'])road = road.reset_index(drop=True)road = road[['road_id','road_addr','geometry']]
The code performs a geometry explosion to split multi-part geometries (e.g., MultiPolygon or MultiLineString) into individual geometries (e.g., Polygon or LineString). After exploding, it resets the index to maintain a clean, sequential index for further data processing.
Code
# Reset the index to maintain a clean sequential index after the explosionparcel = parcel.explode(index_parts=False).reset_index(drop=True)road = road.explode(index_parts=False).reset_index(drop=True)
Geometry Extraction
In this step, we decompose each road line into individual segments, which helps facilitate accurate spatial matching in later analysis. In other words, splitting the road lines into smaller segments allows us to precisely assign each parcel boundary to its nearest road segment, improving spatial alignment and analytical precision.
Code
# Initialize lists to store line segments and corresponding addressesline_strings = []addrs = []linear_ids = []# Iterate over rows in roadfor idx, row in road.iterrows(): line = row['geometry'] # Assume this is a LineString geometry addr = row['road_addr'] linear_id = row['road_id']if line.is_valid andisinstance(line, LineString):for i inrange(len(line.coords) -1): current_line = LineString([line.coords[i], line.coords[i +1]]) line_strings.append(current_line) addrs.append(addr) linear_ids.append(linear_id)else:print(f"Invalid or non-LineString geometry detected: {line}")# Create GeoDataFrame for the split road segmentsroad_seg = gpd.GeoDataFrame({'geometry': line_strings, 'road_addr': addrs, 'road_id': linear_ids}, crs=road.crs)road_seg = road_seg.to_crs(3857)
Address Matching
This step is crucial because the two datasets are collected from different sources, which may lead to slight variations in the recorded addresses. Although both the road and parcel datasets contain address information, discrepancies can arise. For example:
- Road address: Kamyrn Rd / Houpu Road
- Parcel address: 1230 Kamyrn Road / 1230 Hpu Rood
As shown above, minor differences such as abbreviations or misspellings can make direct matching challenging. To address this issue, we use the fuzzywuzzy and rtree libraries to implement a robust matching method that links nearst road addresses to their corresponding parcel segments. - fuzzywuzzy: A library used for fuzzy string matching, which helps identify similar but non-identical addresses by calculating a similarity score. - rtree: A spatial indexing library used to efficiently find and match spatial features based on their proximity, improving the accuracy of address-to-parcel assignments.
01.Coordinate Transformation
This step converts the coordinate reference systems (CRS) of both extracted_parcel and extracted_road to a projected CRS (EPSG: 3857) to ensure spatial consistency for subsequent spatial operations.
Code
# transfer the crs to projected crsparcel = parcel.to_crs(3857)road = road.to_crs(parcel.crs)
02.Spatial Filtering Using cKDtree
To match the address names between road segments and parcels, we first need to identify the nearest road. However, the nearest road may not always have the exact same name as the parcel’s address. To improve the matching accuracy, we identify the n nearest roads for each parcel (in this case, n = 50). This approach provides multiple candidate road segments for each parcel, increasing the chances of finding a correct match in subsequent processes. The code calculates the centroid coordinates (x, y) of both road segments and parcel geometries. It then uses the cKDTree from scipy to find the 50 nearest roads for each parcel based on their centroid locations. The results will update in the extracted_parcel GeoDataFrame, adding Nearest_Road columns to indicate the closest road names for each parcel. Finally, the temporary x and y columns are dropped to maintain a clean dataset. This process enables efficient spatial address matching between parcels and road segments for further analysis.
Code
# Find the centroid coordinate for each road and parcelroad_seg['x'] = road_seg.geometry.apply(lambda geom: geom.centroid.x)road_seg['y'] = road_seg.geometry.apply(lambda geom: geom.centroid.y)parcel['x'] = parcel.geometry.apply(lambda geom: geom.centroid.x)parcel['y'] = parcel.geometry.apply(lambda geom: geom.centroid.y)# find the nearest road by using cKDTreen =50tree = cKDTree(road_seg[['x', 'y']])distances, indices = tree.query(parcel[['x', 'y']], k=n) # find the nearest n roads# Create a temporary DataFrame to store the nearest road namesnearest_road_names = pd.DataFrame({f'Nearest_Road_{i+1}_Address': road_seg.iloc[indices[:, i]].road_addr.valuesfor i inrange(n)})# Concatenate the new columns with the original DataFrameparcel = pd.concat([parcel, nearest_road_names], axis=1)# Drop the x, y columnparcel = parcel.drop(columns=['x', 'y'])
parcel_id
parcel_addr
landuse_spec
parcel_label
geometry
Nearest_Road_1_FULLNAME
Nearest_Road_2_FULLNAME
Nearest_Road_3_FULLNAME
Nearest_Road_4_FULLNAME
Nearest_Road_5_FULLNAME
Nearest_Road_6_FULLNAME
Nearest_Road_7_FULLNAME
Nearest_Road_8_FULLNAME
Nearest_Road_9_FULLNAME
Nearest_Road_10_FULLNAME
Nearest_Road_11_FULLNAME
Nearest_Road_12_FULLNAME
Nearest_Road_13_FULLNAME
Nearest_Road_14_FULLNAME
Nearest_Road_15_FULLNAME
Nearest_Road_16_FULLNAME
Nearest_Road_17_FULLNAME
Nearest_Road_18_FULLNAME
Nearest_Road_19_FULLNAME
Nearest_Road_20_FULLNAME
Nearest_Road_21_FULLNAME
Nearest_Road_22_FULLNAME
Nearest_Road_23_FULLNAME
Nearest_Road_24_FULLNAME
Nearest_Road_25_FULLNAME
Nearest_Road_26_FULLNAME
Nearest_Road_27_FULLNAME
Nearest_Road_28_FULLNAME
Nearest_Road_29_FULLNAME
Nearest_Road_30_FULLNAME
Nearest_Road_31_FULLNAME
Nearest_Road_32_FULLNAME
Nearest_Road_33_FULLNAME
Nearest_Road_34_FULLNAME
Nearest_Road_35_FULLNAME
Nearest_Road_36_FULLNAME
Nearest_Road_37_FULLNAME
Nearest_Road_38_FULLNAME
Nearest_Road_39_FULLNAME
Nearest_Road_40_FULLNAME
Nearest_Road_41_FULLNAME
Nearest_Road_42_FULLNAME
Nearest_Road_43_FULLNAME
Nearest_Road_44_FULLNAME
Nearest_Road_45_FULLNAME
Nearest_Road_46_FULLNAME
Nearest_Road_47_FULLNAME
Nearest_Road_48_FULLNAME
Nearest_Road_49_FULLNAME
Nearest_Road_50_FULLNAME
0
400151
2717 E BELKNAP ST
C
NaN
POLYGON ((-10832192.750619514 3864892.01523430...
Blandin St
US Hwy 377
E Belknap St
Marshall St
Blandin St
Grace Ave
Noble Ave
Noble Ave
Grace Ave
Noble Ave
E Belknap St
US Hwy 377
Noble Ave
Blandin St
Blandin St
Grace Ave
Marshall St
Noble Ave
US Hwy 377
E Belknap St
Grace Ave
N Sylvania Ave
E Belknap St
US Hwy 377
N Sylvania Ave
Noble Ave
N Sylvania Ave
N Sylvania Ave
Grace Ave
Emma St
E Belknap St
US Hwy 377
N Sylvania Ave
Blandin St
Blandin St
Plumwood St
Marshall St
E Belknap St
US Hwy 377
N Sylvania Ave
E Belknap St
US Hwy 377
Noble Ave
N Sylvania Ave
Pittsburg Pl
Race St
Pittsburg Pl
N Judkins St
Race St
Juanita St
1
403412
3000 MARIGOLD AVE
R
NaN
POLYGON ((-10831742.722703427 3866447.98916702...
N Chandler Dr
Marigold Ave
N Chandler Dr
Primrose Ave
Primrose Ave
Marigold Ave
N Chandler Dr
N Chandler Dr
Primrose Ave
Marigold Ave
Honeysuckle Ave
N Chandler Dr
Primrose Ave
Primrose Ave
N Chandler Dr
Marigold Ave
N Riverside Dr
Honeysuckle Ave
Honeysuckle Ave
Primrose Ave
N Chandler Dr
N Riverside Dr
Blandin St
Yucca Ave
Primrose Ave
Yucca Ave
N Riverside Dr
Blandin St
Primrose Ave
Primrose Ave
N Chandler Dr
Blandin St
Honeysuckle Ave
Marigold Ave
Marigold Ave
N Riverside Dr
Primrose Ave
Carnation Ave
Yucca Ave
N Riverside Dr
N Riverside Dr
Blandin St
Blandin St
Carnation Ave
N Chandler Dr
Yucca Ave
N Chandler Dr
Honeysuckle Ave
Clary Ave
Honeysuckle Ave
2
403410
3012 MARIGOLD AVE
R
NaN
POLYGON ((-10831697.814370392 3866447.98820623...
Marigold Ave
N Chandler Dr
Primrose Ave
N Chandler Dr
Marigold Ave
Primrose Ave
N Chandler Dr
Primrose Ave
N Chandler Dr
Marigold Ave
N Riverside Dr
N Chandler Dr
Honeysuckle Ave
Primrose Ave
Honeysuckle Ave
N Riverside Dr
N Chandler Dr
N Riverside Dr
Yucca Ave
Marigold Ave
N Chandler Dr
Primrose Ave
Primrose Ave
Honeysuckle Ave
Marigold Ave
N Riverside Dr
Honeysuckle Ave
Yucca Ave
Primrose Ave
N Riverside Dr
N Riverside Dr
N Chandler Dr
Primrose Ave
Blandin St
Carnation Ave
Blandin St
Honeysuckle Ave
Primrose Ave
Bolton St
Primrose Ave
Primrose Ave
Bolton St
Yucca Ave
Primrose Ave
Bolton St
Blandin St
N Chandler Dr
N Riverside Dr
Marigold Ave
Yucca Ave
3
403409
3016 MARIGOLD AVE
R
NaN
POLYGON ((-10831675.720805798 3866447.98629809...
Marigold Ave
Marigold Ave
Primrose Ave
N Chandler Dr
N Chandler Dr
Primrose Ave
N Riverside Dr
N Chandler Dr
Primrose Ave
N Chandler Dr
N Riverside Dr
Honeysuckle Ave
Marigold Ave
N Chandler Dr
Honeysuckle Ave
N Riverside Dr
Primrose Ave
N Chandler Dr
Marigold Ave
Yucca Ave
Primrose Ave
Honeysuckle Ave
N Riverside Dr
N Chandler Dr
Primrose Ave
N Riverside Dr
N Riverside Dr
Honeysuckle Ave
Marigold Ave
Yucca Ave
Bolton St
Honeysuckle Ave
Primrose Ave
N Chandler Dr
Primrose Ave
Primrose Ave
Bolton St
Carnation Ave
Bolton St
Yucca Ave
Primrose Ave
Blandin St
Blandin St
N Riverside Dr
Primrose Ave
N Chandler Dr
Primrose Ave
Blandin St
Clary Ave
N Chandler Dr
4
403408
3020 MARIGOLD AVE
R
NaN
POLYGON ((-10831652.897093678 3866449.42460290...
Marigold Ave
Marigold Ave
Primrose Ave
Primrose Ave
N Riverside Dr
N Chandler Dr
N Chandler Dr
N Riverside Dr
N Chandler Dr
Primrose Ave
Honeysuckle Ave
N Chandler Dr
N Riverside Dr
Honeysuckle Ave
N Chandler Dr
Marigold Ave
Marigold Ave
Primrose Ave
Honeysuckle Ave
Yucca Ave
N Chandler Dr
Primrose Ave
N Riverside Dr
N Chandler Dr
N Riverside Dr
N Riverside Dr
Bolton St
Honeysuckle Ave
Primrose Ave
Primrose Ave
Bolton St
Bolton St
Primrose Ave
Yucca Ave
Yucca Ave
Honeysuckle Ave
Marigold Ave
N Chandler Dr
Carnation Ave
Primrose Ave
N Riverside Dr
Primrose Ave
Blandin St
N Chandler Dr
Carnation Ave
Bolton St
Blandin St
Clary Ave
Primrose Ave
Clary Ave
03.Field Similarity Matching Using Fuzzywuzzy
This code performs address matching between parcel addresses (Situs_Addr) and the nearest road segments name by using fuzzy string matching. It first removes spaces and converts both addresses and road names to lowercase for consistency. Then, it identifies the top n nearest roads for each parcel and calculates a similarity score using the fuzz.partial_ratio function from the fuzzywuzzy library. The code keeps track of the best match if the similarity score exceeds a predefined threshold (50%). If a match is found, new columns are created to store the matched road segment and its original format. The results are then merged back into the main extracted_parcel GeoDataFrame, and any parcels without a match are labeled as no_match_address and print the count of parcels that could not be matched. This step helps refine address matching by allowing for minor variations and typos in the address data, thereby improving overall matching accuracy between parcels and roads segments.
Code
# The function to find the match address between the n nearst roads segments and parcelsdef check_and_extract_match_info(row):# Remove spaces from parcel_addr parcel_addr = row['parcel_addr'].replace(' ', '').lower()# Dynamically generate a list of the nearest n road names, check if they are not NaN road_names = [row[f'Nearest_Road_{i+1}_Address'].replace(' ', '').lower() if pd.notna(row[f'Nearest_Road_{i+1}_Address']) else''for i inrange(n)]# Define a similarity threshold (e.g., 50%) threshold =50 best_match =None best_similarity =0# Check each road name and record match informationfor road in road_names:if road: # Only proceed if the road name is not empty# Calculate the similarity score using fuzz.partial_ratio similarity = fuzz.partial_ratio(parcel_addr, road)# Keep track of the best matchif similarity > best_similarity and similarity >= threshold: best_similarity = similarity best_match = roadif best_match: match_segment = best_match # Matched road segment original_road = row[f'Nearest_Road_{road_names.index(best_match) +1}_Address'] # Original road name with spacesreturn pd.Series([True, match_segment, original_road])return pd.Series([False, None, None]) # Return False and None if no match found# Step 1: Ensure 'parcel_addr' has no NaN values before applying the functionparcel_clean = parcel.loc[parcel['parcel_addr'].notna()].copy()# Step 2: Apply the check_and_extract_match_info function to add new columnsparcel_clean[['Found_Match', 'match_segment', 'match_road_address']] = parcel_clean.apply(check_and_extract_match_info, axis=1)# Step 3: Merge the newly created columns back into the original 'parcel' DataFrameparcel = parcel.merge(parcel_clean[['Found_Match', 'match_segment', 'match_road_address']], left_index=True, right_index=True, how='left')parcel.loc[parcel['Found_Match'] ==False, 'parcel_label'] ='no_match_address'# Step 4: Count how many rows have 'Found_Match' == Falselen(parcel[parcel['Found_Match'] ==False])
parcel_id
parcel_addr
landuse_spec
parcel_label
geometry
Nearest_Road_1_FULLNAME
Nearest_Road_2_FULLNAME
Nearest_Road_3_FULLNAME
Nearest_Road_4_FULLNAME
Nearest_Road_5_FULLNAME
Nearest_Road_6_FULLNAME
Nearest_Road_7_FULLNAME
Nearest_Road_8_FULLNAME
Nearest_Road_9_FULLNAME
Nearest_Road_10_FULLNAME
Nearest_Road_11_FULLNAME
Nearest_Road_12_FULLNAME
Nearest_Road_13_FULLNAME
Nearest_Road_14_FULLNAME
Nearest_Road_15_FULLNAME
Nearest_Road_16_FULLNAME
Nearest_Road_17_FULLNAME
Nearest_Road_18_FULLNAME
Nearest_Road_19_FULLNAME
Nearest_Road_20_FULLNAME
Nearest_Road_21_FULLNAME
Nearest_Road_22_FULLNAME
Nearest_Road_23_FULLNAME
Nearest_Road_24_FULLNAME
Nearest_Road_25_FULLNAME
Nearest_Road_26_FULLNAME
Nearest_Road_27_FULLNAME
Nearest_Road_28_FULLNAME
Nearest_Road_29_FULLNAME
Nearest_Road_30_FULLNAME
Nearest_Road_31_FULLNAME
Nearest_Road_32_FULLNAME
Nearest_Road_33_FULLNAME
Nearest_Road_34_FULLNAME
Nearest_Road_35_FULLNAME
Nearest_Road_36_FULLNAME
Nearest_Road_37_FULLNAME
Nearest_Road_38_FULLNAME
Nearest_Road_39_FULLNAME
Nearest_Road_40_FULLNAME
Nearest_Road_41_FULLNAME
Nearest_Road_42_FULLNAME
Nearest_Road_43_FULLNAME
Nearest_Road_44_FULLNAME
Nearest_Road_45_FULLNAME
Nearest_Road_46_FULLNAME
Nearest_Road_47_FULLNAME
Nearest_Road_48_FULLNAME
Nearest_Road_49_FULLNAME
Nearest_Road_50_FULLNAME
Found_Match
match_segment
match_road_address
0
400151
2717 E BELKNAP ST
C
NaN
POLYGON ((-10832192.750619514 3864892.01523430...
Blandin St
US Hwy 377
E Belknap St
Marshall St
Blandin St
Grace Ave
Noble Ave
Noble Ave
Grace Ave
Noble Ave
E Belknap St
US Hwy 377
Noble Ave
Blandin St
Blandin St
Grace Ave
Marshall St
Noble Ave
US Hwy 377
E Belknap St
Grace Ave
N Sylvania Ave
E Belknap St
US Hwy 377
N Sylvania Ave
Noble Ave
N Sylvania Ave
N Sylvania Ave
Grace Ave
Emma St
E Belknap St
US Hwy 377
N Sylvania Ave
Blandin St
Blandin St
Plumwood St
Marshall St
E Belknap St
US Hwy 377
N Sylvania Ave
E Belknap St
US Hwy 377
Noble Ave
N Sylvania Ave
Pittsburg Pl
Race St
Pittsburg Pl
N Judkins St
Race St
Juanita St
True
ebelknapst
E Belknap St
1
403412
3000 MARIGOLD AVE
R
NaN
POLYGON ((-10831742.722703427 3866447.98916702...
N Chandler Dr
Marigold Ave
N Chandler Dr
Primrose Ave
Primrose Ave
Marigold Ave
N Chandler Dr
N Chandler Dr
Primrose Ave
Marigold Ave
Honeysuckle Ave
N Chandler Dr
Primrose Ave
Primrose Ave
N Chandler Dr
Marigold Ave
N Riverside Dr
Honeysuckle Ave
Honeysuckle Ave
Primrose Ave
N Chandler Dr
N Riverside Dr
Blandin St
Yucca Ave
Primrose Ave
Yucca Ave
N Riverside Dr
Blandin St
Primrose Ave
Primrose Ave
N Chandler Dr
Blandin St
Honeysuckle Ave
Marigold Ave
Marigold Ave
N Riverside Dr
Primrose Ave
Carnation Ave
Yucca Ave
N Riverside Dr
N Riverside Dr
Blandin St
Blandin St
Carnation Ave
N Chandler Dr
Yucca Ave
N Chandler Dr
Honeysuckle Ave
Clary Ave
Honeysuckle Ave
True
marigoldave
Marigold Ave
04.Extracted Useful Columns
Ultimately, to simplify the GeoDataframe, we need to re-extract and update the data based on the relevant columns to retain only the necessary information.
Code
# Extract the useful columnsparcel = parcel[['Prop_ID','GEO_ID','parcel_id','parcel_addr','landuse','landuse_spec','parcel_label','geometry','Found_Match','match_road_address']]